[Python] 파이썬 웹 크롤링 실시간 주가 정보 가져오기
제가 실제로 사용하고 있는 웹 크롤링 소스를 제공해 드릴려고 합니다.
특정 종목의 주가 정보를 실시간으로 읽어와서 명령 프롬프트 창에 출력해주는 프로그램 입니다.
회사 또는 가정에서 주가 창을 보지 못하시는 분들을 위해 종목의 실시간 변동 추이만 확인하실 수 있습니다.
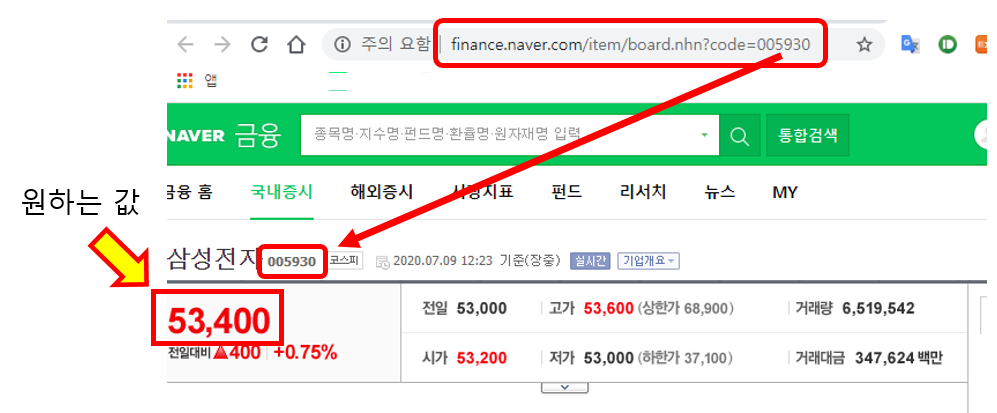
제가 필요한 값은 아래 사진과 같이 네이버 금융 사이트 https://finance.naver.com 에서 해당 종목명 또는 종목 코드 값을 조회해서 주가 정보를 받아 오는 것이 목적입니다.
핵심은 "https://finance.naver.com/item/main.nhn?code=" + company_code 와 같이 구성되어 진다는 것입니다.
https://finance.naver.com/item/main.nhn?code= 값은 똑같고 뒤에는 값은 실제 조회하고 싶은 종목의 종목 코드 값이 들어가면 됩니다.
그럼 코드를 작성해 보도록 하겠습니다.
웹 크롤링을 하기 위해 파이썬의 BeautifulSoup 을 사용했습니다.
BeautifulSoup 란?
HTML 및 XML 문서를 구문 분석하기위한 Python 패키지입니다. 웹 스크래핑에 유용한 HTML에서 데이터를 추출하는 데 사용할 수있는 구문 분석 된 페이지에 대한 구문 분석 트리를 만듭니다
그럼 이제 코드 작성을 위해 코드 편집기 프로그램인 VSCode 를 실행합니다. VS Code가 아닌 다른 편집기를 사용하셔도 상관 없습니다. 메모장에 하셔도 됩니다.
새 파일을 여시고 확장자 py로 된 파이썬 파일을 생성합니다.
[ 모듈 설치 ]
관리자 권한으로 cmd 창을 실행하시고 다음과 같이 명령어를 작성하여 BeautifulSoup과 requests 모듈을 설치합니다.
> pip install beautifulsoup4
>pip install requests
[ 코드 작성 ]
BeautifulSoup 을 사용하기 위해 import 합니다.
from bs4 import BeautifulSoup
현재 시각을 출력하기 위해 datetime을 import 합니다.
from datetime import datetime
url 의 정보를 받아 오기 위한 requests 를 import 합니다.
import requests
1분마다 주가 정보를 받을 수 있게 시간 측정을 위한 time 을 import 합니다.
import time
여기까지 상단에 총 4개가 import 되었습니다.
from bs4 import BeautifulSoup
from datetime import datetime
import requests
import time
이제 함수 2개를 작성할 것입니다.
첫 번째 함수
종목 코드를 입력 받아 해당 종목 코드를 검색한 네이버 검색 페이지의 html 코드를 parser 한 결과 값을 리턴해 주는 함수 입니다.
두 번째 함수
html.parser 함 첫 번째 함수 결과 값을 바탕으로 해당 종목 코드의 현재 가격을 가져오는 함수 입니다.
그럼 첫 번째 함수를 작성하겠습니다.
def get_code(company_code):
url = "https://finance.naver.com/item/main.nhn?code=" + company_code
result = requests.get(url)
bs_obj = BeautifulSoup(result.content, "html.parser")
return bs_obj함수명: get_code
company_code 매개변수 값을 get_code 함수로 던져줍니다.
url 변수에 전달 받은 company_code 값이 더해져
하나의 값 https://finance.naver.com/item/main.nhn?code=company_code 을 대입합니다.
해당 url 값을 BeautifulSoup을 이용하여 코드를 전부 bs_obj 라는 변수에 대입합니다.
두 번째 함수를 작성하겠습니다.
def get_price(company_code):
bs_obj = get_code(company_code)
no_today = bs_obj.find("p", {"class": "no_today"})
blind = no_today.find("span", {"class": "blind"})
now_price = blind.text
return now_price함수명: get_price
company_code 매개변수 값을 get_price 함수로 던져줍니다.
첫 번째 함수를 이용해서 종목 코드를 검색한 창의 HTML 코드를 bs_obj 변수에 대입합니다.
HTML 코드 중 제가 필요한 해당 종목의 값을 가져와 now_price 변수에 대입합니다.
최종 now_price 값을 리턴합니다.
메인 코드
company_codes = ["종목코드", "종목코드", "종목코드", "종목코드"]
while True:
now = datetime.now()
print (now)
for item in company_codes:
now_price = get_price(item)
print(now_price)
print("-------------------------------")
time.sleep(60)company_codes 배열에 출력하고자 하는 종목코드를 넣습니다. 1개든 2개든.. 원하는 종목 코드를 모두 넣습니다.
While 반복문을 통해
현재 시각을 출력하고 해당 종목 코드를 첫 번째부터 값을 화면에 출력합니다.
배열의 마지막 값까지 종목 값을 화면에 출력 후 "----------------------------" 로 구분할 수 있는 표시 값을 넣습니다.
60초 후에 다시 while문이 반복됩니다.
해당 반복문의 종료는 프로그램 종료 입니다.
While문의 참 값을 True 로 주었기 때문에 무한루프가 돌게 되는 것입니다.
[ 전체 소스 코드 ]
from bs4 import BeautifulSoup
from datetime import datetime
import requests
import time
def get_code(company_code):
url = "https://finance.naver.com/item/main.nhn?code=" + company_code
result = requests.get(url)
bs_obj = BeautifulSoup(result.content, "html.parser")
return bs_obj
def get_price(company_code):
bs_obj = get_code(company_code)
no_today = bs_obj.find("p", {"class": "no_today"})
blind = no_today.find("span", {"class": "blind"})
now_price = blind.text
return now_price
company_codes = ["271980", "042510", "014285", "042040"]
while True:
now = datetime.now()
print (now)
for item in company_codes:
now_price = get_price(item)
print(now_price)
print("-------------------------------")
time.sleep(60)
감사합니다.
'IT > Python' 카테고리의 다른 글
| 파이썬 조건문 if 문 (0) | 2022.04.28 |
|---|---|
| 파이썬 설치하는 방법 (0) | 2022.04.27 |
| [Python] 파이썬 - 특정 시간에 자동 실행하는 프로그램 (0) | 2020.10.12 |
| [Python] 파이썬 웹 크롤링 - 네이버 환율 정보 가져오기 (2) | 2020.05.25 |
| [Python] 파이썬 Visual Studio Code 개발 환경 구축 (0) | 2020.05.25 |



댓글