[Python] 파이썬 웹 크롤링 - 네이버 환율 정보 가져오기
웹 크롤링이란
크롤링(crawling) 혹은 스크레이핑(scraping)은 조직적, 자동화된 방법으로 웹 페이지를 탐색하여 그대로 가져와서 데이터를 추출해 내는 행위를 뜻합니다. 크롤링하는 소프트웨어는 크롤러(crawler)라고 부릅니다.
검색 엔진과 같은 여러 사이트에서는 데이터의 최신 상태 유지를 위해 웹 크롤링합니다. 웹 크롤러는 대체로 방문한 사이트의 모든 페이지의 복사본을 생성하는 데 사용되며, 검색 엔진은 이렇게 생성된 페이지를 보다 빠른 검색을 위해 인덱싱합니다. 또한 크롤러는 링크 체크나 HTML 코드 검증과 같은 웹 사이트의 자동 유지 관리 작업을 위해 사용되기도 하며, 자동 이메일 수집과 같은 웹 페이지의 특정 형태의 정보를 수집하는 데도 사용됩니다.
웹 크롤링을 위한 소프트웨어
현재 Python이 이 분야의 선두주자입니다. 컴퓨터 프로그래밍이 익숙하지 않은 비전공자들인 인문학이나 통계 분야의 종사자들이 쓰기 쉽도록 라이브러리들이 발달하면서 급격히 발전하고 있습니다. 대표적인 파이썬 라이브러리의 예로 beautifulsoup등이 있습니다.
필자는 Python 개발 도구로 VSCode를 사용하고 있습니다. VS Code는 Visual Studio Code의 약자로 설치 방법은 아래 url를 참고 부탁드립니다.
VSCode 설치 방법
[개발도구] VSCode 설치와 한글 설정 방법
VSCode 란 비주얼 스튜디오 코드(영어: Visual Studio Code)는 마이크로소프트가 윈도우, macOS, 리눅스용으로 개발한 무료 소스 코드 편집기입니다. 디버깅 지원과 Git 제어, 구문 강조 기능등이 포함되어
yjshin.tistory.com
VSCode의 Python 개발 환경 구축
[Python] 파이썬 Visual Studio Code 개발 환경 구축
Visual Studio Code, VSCode 에서 파이썬(Python) 연결 설정하는 방법에 대한 글입니다. VSCode는 무료 편집기 툴로써 파이썬을 VSCode 에서 실행 구동 및 설정 변경, 코드 작성 등을 하는 것입니다. Visual Studi..
yjshin.tistory.com
네이버 환율 정보 가져오기
웹 크롤링의 대표적인 예입니다.
네이버 금용(http://finance.naver.com)에서 HTMl 텍스트를 읽어 출력하는 코드 템플릿 입니다.
from bs4 import BeautifulSoup
import urllib.request as req
url = "https://finance.naver.com/marketindex/"
res = req.urlopen(url)
soup = BeautifulSoup(res,"html.parser", from_encoding='euc-kr')
name_nation = soup.select('h3.h_lst > span.blind')
name_price = soup.select('span.value')
i = 0
for c_list in soup:
try:
print(i+1,name_nation[i].text, name_price[i].text)
i = i + 1
except IndexError:
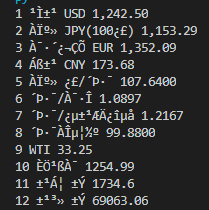
pass결과 화면

결과 값이 아래와 같이 나온 다면
soup = BeautifulSoup(res,"html.parser", from_encoding='euc-kr')
위 구문에서 from_endoding='euc-kr' 이 먹히지 않은 것입니다.
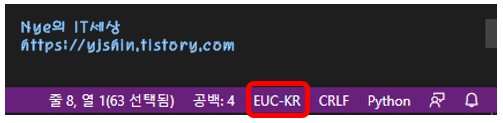
VSCode 하단에 EUC-KR 부분을 클릭하여 EUC-KR로 변경해 주시면 됩니다.
'IT > Python' 카테고리의 다른 글
| 파이썬 조건문 if 문 (0) | 2022.04.28 |
|---|---|
| 파이썬 설치하는 방법 (0) | 2022.04.27 |
| [Python] 파이썬 - 특정 시간에 자동 실행하는 프로그램 (0) | 2020.10.12 |
| [Python] 파이썬 웹 크롤링 실시간 주가 정보 가져오기 (10) | 2020.07.09 |
| [Python] 파이썬 Visual Studio Code 개발 환경 구축 (0) | 2020.05.25 |



댓글