[AI] OpenAI Sora 사용법과 출시일 및 가격 정보, 텍스트로 영상 만들기
OpenAI가 선보인 SORA는 텍스트 입력을 바탕으로 최대 1분 길이의 영상을 제작할 수 있는 AI 서비스입니다. 사용자가 제공한 텍스트 설명을 기반으로 실제와 유사한 동영상을 만들어내는 이 기술을 통해, 당신도 바로 창의적인 영상 제작자가 될 수 있습니다. SORA를 이용해, 상상력을 자극하는 다양한 시나리오를 영상으로 구현해보세요.
Sora와 유사한 AI 영상 플랫폼
기존 AI 기반 영상 생성 및 편집 플랫폼은 다음과 같은 것들이 있습니다.
- Runway: 비디오 편집 및 이미지 생성을 위한 AI 플랫폼. Runway
- Descript: 오디오 및 비디오의 텍스트 기반 편집을 지원하는 AI 플랫폼. Descript
- Synthesia: 텍스트 입력으로 비디오를 생성할 수 있는 서비스, 가상 아바타 사용. Synthesia
이 서비스들의 비디오 생성 가능 시간은 서비스마다 다르며, 상세 정보는 각각의 웹사이트에서 확인할 수 있습니다
OpenAI Sora 사용법
SORA는 단순한 장면 묘사를 넘어, 풍부한 감성과 상세한 시나리오까지 영상으로 전환할 수 있는 능력을 갖추고 있습니다.
예를 들어 "도쿄의 밤거리를 걷는 멋진 여성"이나 "2056년 나이지리아 라고스의 일상" 같은 생생한 시나리오를 텍스트로 제공함으로써, 이를 기반으로 한 영상을 생성할 수 있습니다.

위와 같이 ChatGPT 형식의 프롬프트 창을 이용하여 작성하게 될 것이라 판단됩니다.
프롬프트 예시 1. 도쿄 밤거리를 걷는 여성
Prompt: A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.
프롬프트 출처: openai sora
프롬프트 예시 2. 2056년의 나이지리아 라고스 사람들의 일상
Prompt: A beautiful homemade video showing the people of Lagos, Nigeria in the year 2056. Shot with a mobile phone camera.
프롬프트 출처: openai sora
다양한 현실적인 영상을 텍스트로 제작하기
Sora를 활용하여 현실감 있는 영상도 제작 가능합니다. 사용자가 장면을 상세하게 묘사하면 할수록 영상의 퀄리티는 올라가게 됩니다.
이는 영상 제작 시, 애니메이션, 공상과학 영화, 실제와 같은 장면 재현 등 다양한 스타일의 영상을 만들어낼 수 있습니다.
프롬프트 예시 1. 눈 덮인 겨울 풍경의 매머드
Prompt: Several giant wooly mammoths approach treading through a snowy meadow, their long wooly fur lightly blows in the wind as they walk, snow covered trees and dramatic snow capped mountains in the distance, mid afternoon light with wispy clouds and a sun high in the distance creates a warm glow, the low camera view is stunning capturing the large furry mammal with beautiful photography, depth of field.
프롬프트 출처: openai sora
프롬프트 예시 2. 우주인의 탐사 모습
Prompt: A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors.
프롬프트 출처: openai sora
프롬프트 예시3. 오프로드를 달리는 SUV 차량을 촬영하는 드론 시점
Prompt: The camera follows behind a white vintage SUV with a black roof rack as it speeds up a steep dirt road surrounded by pine trees on a steep mountain slope, dust kicks up from it’s tires, the sunlight shines on the SUV as it speeds along the dirt road, casting a warm glow over the scene. The dirt road curves gently into the distance, with no other cars or vehicles in sight. The trees on either side of the road are redwoods, with patches of greenery scattered throughout. The car is seen from the rear following the curve with ease, making it seem as if it is on a rugged drive through the rugged terrain. The dirt road itself is surrounded by steep hills and mountains, with a clear blue sky above with wispy clouds.
프롬프트 출처: openai sora
Sora 애니메이션 영상 만들기
ChatGPT의 Sora를 활용하여 애니메이션 영상도 만들 수 있습니다.
프롬프트 예시 1. 춤을 추는 애니메이션 캥거루
Prompt: A cartoon kangaroo disco dances.
프롬프트 출처: openai sora
프롬프트 예시 2. 너구리 같은 케릭터가 숲을 체험하는 모습
Prompt: 3D animation of a small, round, fluffy creature with big, expressive eyes explores a vibrant, enchanted forest. The creature, a whimsical blend of a rabbit and a squirrel, has soft blue fur and a bushy, striped tail. It hops along a sparkling stream, its eyes wide with wonder. The forest is alive with magical elements: flowers that glow and change colors, trees with leaves in shades of purple and silver, and small floating lights that resemble fireflies. The creature stops to interact playfully with a group of tiny, fairy-like beings dancing around a mushroom ring. The creature looks up in awe at a large, glowing tree that seems to be the heart of the forest.
프롬프트 출처: openai sora
Sora SF 동영상 만들기
사이버보그 로봇이나 미래 도시 등의 모습을 영상으로 만들 수 있습니다.
프롬프트 예시 1. 미래도시 로봇
Prompt: The story of a robot’s life in a cyberpunk setting.
프롬프트 출처: openai sora
프롬프트 예시 2. 아틀란티스 같은 뉴욕 도시를 헤엄치는 물고기
Prompt: New York City submerged like Atlantis. Fish, whales, sea turtles and sharks swim through the streets of New York.
프롬프트 출처: openai sora
프롬프트 예시 3. 구름맨이 지구를 향해 번개를 쏘는 장면
Prompt: A giant, towering cloud in the shape of a man looms over the earth. The cloud man shoots lighting bolts down to the earth.
프롬프트 출처: openai sora
Sora 기술 개요
OpenAI는 자사의 공식 홈페이지에 게시된 기술 문서를 통해 Sora 프로젝트의 복잡한 훈련 메커니즘에 대해 설명하였습니다. 이 문서에서는 Sora가 어떻게 이미지와 영상을 생성하는지 상세하게 설명되어 있습니다.
Sora의 기술 개발 과정과 기술적 기능들을 간략하게 소개하겠습니다.
Sora 개발 과정
OpenAI의 이전 성공작, ChatGPT는 사용자의 질문을 토큰화하여 이를 분석하고 학습함으로써 맞춤형 답변을 제공합니다. 이러한 토큰화 과정을 Sora 프로젝트에 적용하여, 시각적 데이터를 더욱 효과적으로 처리할 수 있게 되었습니다.
시각적 데이터의 세분화
Sora는 시각적 요소를 작은 단위인 '패치'로 분할하여 처리합니다. 이는 텍스트 데이터를 처리하는 기존의 방식을 시각적 데이터에 적용한 것으로, 이미지와 비디오의 다양한 속성을 효율적으로 학습할 수 있게 해줍니다.
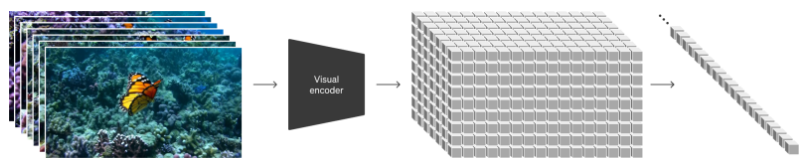
영상 생성과 향상된 품질
Sora는 확산 변환기 모델을 사용하여 고품질의 이미지와 비디오를 생성합니다.
이 모델은 이미지 생성과 영상 처리에 있어서 시간적 연속성과 복잡한 패턴을 효과적으로 다룰 수 있습니다.
확산 모델은 점차적으로 잡음을 제거해 나가며, 변환기 모델은 데이터의 다양한 부분 간의 관계를 학습합니다.

다양한 해상도와 비디오 형식 지원
Sora는 다양한 해상도와 종횡비를 지원하며, 사용자가 원하는 크기와 형식으로 비디오를 쉽게 조정할 수 있습니다.
이를 통해 기존의 비디오 편집 도구에서 발생할 수 있는 문제를 최소화하며, 사용자에게 더욱 풍부한 비디오 생성 경험을 제공합니다.
추가 기능과 활용 가능성
Sora는 이미지 애니메이션화, 비디오 확장, 텍스트 기반의 비디오 편집, 다중 비디오 연결 등 다양한 기능을 제공합니다.
이러한 기능들을 통해 사용자는 창의적인 비디오 콘텐츠를 쉽게 만들고, 다양한 상황에 맞게 조정할 수 있습니다.
이미지 애니메이션화
정적인 이미지와 텍스트를 입력하면 이를 기반으로 애니메이션을 생성합니다.

비디오 확장 기능
특정 영상을 첨부하고 과거 장면을 상상하여 입력하면 과거 시점까지 영상을 제작해줍니다.
물론 미래도 가능합니다.
텍스트로 비디오 편집하기
수정이 필요한 기존 영상을 제공하고 수정할 부분을 프롬프트에 입력하면 Sora는 영상을 수정하여 생성해줍니다.
2개 이상의 다른 비디오의 전환
완전 다른 2개 이상의 비디오를 입력하여 자연스럽게 연결해달라고 요청하면 이를 자연스럽게 전화되는 영상을 생성해줍니다.
Sora 을 활용한 비디오 게임 랜더링
특정 게임의 영상까지 생성 가능합니다.
[AI] OpenAI Sora Text to Video 생성 모델, 게임 랜더링 기능 포함 (feat. 마인크래프트)
OpenAI가 최근 발표한 동영상 생성 도구, Sora는 단순한 영상 제작을 넘어선 기능을 제공합니다. 이번에 공개된 Sora는 영화 품질의 동영상뿐만 아니라, 비디오 게임에도 활용될 수 있는 기능을 탑재
yjshin.tistory.com
Sora 사용 시 주의사항
SORA를 사용할 때는 OpenAI의 사용 정책을 준수하는 것이 중요합니다. 극단적인 폭력, 성적 내용, 혐오 표현 등 사용 정책에 위배되는 내용을 피해야 하며, 모든 영상은 사용 정책을 준수하는지 검토 과정을 거칩니다.
현재 SORA는 크리에이티브 전문가들에게 우선 접근을 제공하며, 사용자 피드백을 바탕으로 지속적으로 개선되고 있습니다.
Q&A
Q1. 어떻게 Sora의 패치 기반 처리가 텍스트 토큰 처리와 비교하여 시각적 데이터 분석에 있어서 우위를 차지하나요?
A.Sora의 패치 기반 처리는 전통적인 텍스트 토큰 처리 방식을 시각적 데이터에 적용한 것으로, 여러 가지 면에서 시각적 데이터 분석에 있어서 우위를 차지합니다. 이러한 우위는 주로 데이터의 성격과 처리 방식의 차이에서 비롯됩니다.
1. 고차원 데이터의 효율적 처리
- 텍스트 데이터는 주로 1차원적인 성격을 가지며, 텍스트 토큰 처리는 이러한 1차원 데이터를 분석하고 학습하는 데 최적화되어 있습니다. 이에 반해, 시각적 데이터는 고차원적 특성(예: 색상, 형태, 공간적 관계 등)을 가지고 있습니다. 패치 기반 처리는 이러한 고차원 데이터를 효과적으로 분할하고 분석하여, 시각적 요소의 복잡한 패턴과 관계를 더 잘 이해할 수 있게 합니다.
2. 상세한 특성 학습
- 텍스트 토큰화는 단어나 구의 의미를 분석하는 데 집중하지만, 패치 기반 처리는 이미지나 비디오의 작은 부분 하나하나에서 나타나는 세밀한 시각적 특성(예: 질감, 그라데이션, 경계선 등)을 학습합니다. 이를 통해 Sora는 더 복잡하고 세밀한 시각적 정보를 처리하고 재현할 수 있는 능력을 갖추게 됩니다.
3. 다양한 해상도와 종횡비에 대한 유연성
- 패치 기반 처리는 다양한 해상도와 종횡비의 이미지나 비디오를 효율적으로 처리할 수 있는 유연성을 제공합니다. 이는 텍스트 처리에서는 고려할 필요가 없는 부분이지만, 시각적 데이터를 다룰 때 매우 중요한 요소입니다. Sora는 패치를 통해 다양한 형태의 시각적 데이터를 일관되게 분석하고 학습할 수 있으며, 이는 사용자가 원하는 대로 콘텐츠를 생성하거나 수정하는 데 큰 장점이 됩니다.
4. 복잡한 시각적 패턴의 인식과 재현
- 패치 기반 접근 방식은 이미지나 비디오 내의 복잡한 시각적 패턴과 구조를 인식하고 재현하는 데 뛰어난 능력을 보입니다. 이는 시각적 데이터의 고유한 특성을 학습하여, 실제와 같은 이미지나 비디오를 생성하는 데 필수적인 요소입니다.
5. 시각적 데이터의 시간적 연속성 분석
- 비디오 데이터의 경우, 패치 기반 처리는 각 프레임 사이의 시간적 연속성과 변화를 분석하는 데 탁월합니다. 이는 텍스트 토큰 처리에서는 다루기 어려운, 시각적 데이터 고유의 도전 과제입니다. Sora는 이를 통해 비디오의 자연스러운 흐름과 연속성을 이해하고 재현할 수 있습니다.
이러한 점들을 종합해 볼 때, Sora의 패치 기반 처리는 전통적인 텍스트 토큰 처리 방식에 비해 시각적 데이터 분석에 있어서 더 깊이 있고, 세밀하며, 유연한 접근을 가능하게 합니다.
Q2. 확산 변환기 모델이 이미지와 비디오 생성에 있어서 기존의 모델들과 어떻게 다른 결과를 가져오나요?
A. 확산 변환기 모델은 이미지와 비디오 생성 분야에서 기존 모델들과 비교하여 몇 가지 중요한 차별점을 가지고 있습니다. 이 모델은 확산 모델과 변환기 모델의 장점을 결합하여, 특히 복잡한 시각적 데이터의 생성과 처리에서 뛰어난 성능을 보입니다. 확산 변환기 모델이 가져오는 주요 차이점을 다음과 같이 설명할 수 있습니다:
1. 고품질의 이미지 및 비디오 생성
- 확산 모델은 점진적으로 잡음을 제거해 나가는 방식으로 고품질의 이미지를 생성합니다. 이 과정에서 초기에 잡음이 많은 데이터를 점차적으로 정제하여, 매우 세밀하고 현실적인 결과물을 만들어냅니다. 변환기 모델은 이러한 과정에 문맥적 이해와 시퀀스 데이터의 복잡한 패턴을 학습하는 능력을 더해줍니다. 이 두 모델의 결합은 이미지와 비디오 생성에 있어서 이전 모델들보다 더욱 정교하고 사실적인 결과물을 가져옵니다.
2. 시간적 연속성과 복잡한 패턴의 처리
- 확산 변환기 모델은 시간에 따른 연속성을 가진 데이터(예: 비디오 프레임)를 처리하는 데 탁월한 능력을 보입니다. 비디오 생성에서는 각 프레임 사이의 복잡한 관계와 시간적 연속성을 모델링해야 합니다. 확산 변환기 모델은 이러한 요구사항을 충족시키며, 시간적 순서를 가진 데이터의 생성에 탁월한 성능을 보여줍니다.
3. 다양한 데이터 유형에 대한 유연성
- 기존 모델들은 특정 유형의 데이터 생성에 최적화되어 있을 수 있지만, 확산 변환기 모델은 이미지, 비디오, 복잡한 시퀀스 데이터 등 다양한 유형의 데이터를 생성하는 데 사용될 수 있습니다. 이는 변환기의 문맥 이해 능력과 확산 모델의 점진적인 데이터 정제 과정이 결합되어 다양한 형태의 데이터에 적응할 수 있기 때문입니다.
4. 창의적인 콘텐츠 생성의 확장성
- 확산 변환기 모델은 사용자가 제공하는 조건(예: 텍스트 프롬프트)에 기반하여 창의적인 콘텐츠를 생성할 수 있습니다. 이는 특히 사용자가 상세한 지시를 통해 원하는 시각적 결과물을 얻고자 할 때 유용합니다. 모델은 입력된 조건을 분석하여, 해당 조건에 맞는 고유한 이미지나 비디오를 생성할 수 있습니다.
5. 복잡한 시나리오의 높은 이해도
- 확산 변환기 모델은 복잡한 시나리오와 데이터 패턴을 이해하고, 이를 바탕으로 고품질의 시각적 콘텐츠를 생성할 수 있는 능력을 가지고 있습니다. 이는 기존 모델들이 단순화하거나 무시할 수 있는 세밀한 디테일과 문맥적 뉘앙스를 포착하고 재현할 수 있음을 의미합니다.
확산 변환기 모델은 이러한 방식으로 기존의 모델들과 구분되며, 이미지와 비디오 생성 분야에서 더욱 현실적이고, 사실적이며, 창의적인 결과물을 가져오는 새로운 가능성을 열어줍니다.

'IT > AI' 카테고리의 다른 글
| 알리바바 EMO AI 모델로 말하고 노래하는 인물 영상 만드는 법 (0) | 2024.02.28 |
|---|---|
| [AI] OpenAI Sora Text to Video 생성 모델, 게임 랜더링 기능 포함 (feat. 마인크래프트) (0) | 2024.02.20 |
| [AI] 스테이블 디퓨전 메모리 부족 문제 해결 방법 (0) | 2023.12.19 |
| [AI] 스테이블 디퓨전 로컬 설치: 초보자를 위한 간편 가이드 (1) | 2023.12.18 |
| [AI] 혁신적인 이미지 생성: GPT-4 프롬프트 작성의 중요성 (1) | 2023.12.18 |




댓글