[암호학] 해시 함수, 해시 알고리즘, 해시 충돌, 해시 자료구조
반응형

1. 개요
해시 함수는 임의의 길이를 갖는 임의의 데이터에 대해 고정된 길이의 데이터로 매핑하는 함수를 말한다.
- 매핑 전 원래 데이터의 값을 키(Key)
- 매핑 후 데이터의 값을 해시 값(hash value)
- 해시 값 + 데이터의 색인 주소를 해시 테이블(Hash table)
- 매핑하는 과정 자체를 해싱(hashing)


2. 특성
- 그리 복잡하지 않은 알고리즘으로 구현되기 때문에, 상대적으로 CPU, 메모리 같은 시스템 자원을 덜 소모한다.
- 같은 입력값에 대해서는 같은 출력 값이 보장되며, 이 출력 값은 가능한 한 고른 범위에 균일하게 분포하는 특성이 있다.
- 특수 목적용으로 해시값을 생성하는 원본과 별도의 값을 입력받아서 같은 입력에 대해 다른 출력 값을 가지게 하는 해시 함수도 존재한다
- 해시 함수는 보통 입력 값의 범위보다 출력 값의 범위가 좁은 경우가 많기 때문에 입력이 다름에도 불구하고 드물게 동일한 값이 출력되는 경우도 존재한다. 이러한 경우를 '충돌'한다고 한다. 위 그림에서 'John Smith'와 'Sandra Dee'의 해시 값이 '02' 해시 충돌을 일으키고 있다. 원칙적으로 해시 함수는 이런 어쩔 수 없는 충돌을 제외하고 의도적으로 충돌을 계산해낼 수 없어야 한다.
3. 해시 사용 예
예1) 비밀번호 저장 용도

예2) 복제문서인지 판별
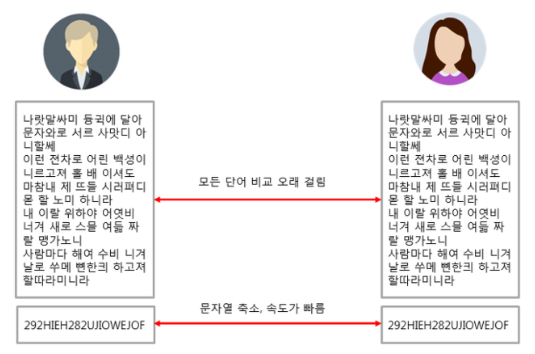
예3) 검색용도

4. 해시를 사용하는 자료 구조
(1) 효율적인 데이터 관리
- 해시 충돌이 발생할 가능성이 있음에도 해시 테이블을 쓰는 이유는 적은 리소스로 많은 데이터를 효율적으로 관리하기 위해서이다.
- 예를 들어, 해시 함수로 하드디스크나 클라우드에 존재하는 무한에 가까운 데이터(키)들을 유한한 개수의 해시값으로 매핑함으로써 작은 크기의 캐쉬 메모리로도 프로세스를 관리할 수 있게 된다.
(2) 빠른 데이터 처리
- 색인(index)에 해시값을 사용함으로써 (정렬을 하지 않고) 모든 데이터를 살피지 않아도 검색과 삽입/삭제를 빠르게 수행할 수 있습니다. 위 그림의 경우 해시함수에 'Lisa Smith'를 입력하면 01 이라는 색인이 생성된다.
- 해시 함수는 언제나 동일한 해시값을 리턴하고, 해당 색인만 알면 해시 테이블의 크기에 상관없이 데이터에 대단히 빠르게 접근할 수 있으며, 색인은 계산이 간단한 함수(상수시간)로 작동하기 때문에 매우 효율적이다. 데이터 액세스(삽입/삭제/탐색)시 계산복잡성을 $O(1)$을 지향한다.
4. 해시테이블
- 해시는 리스트를 사용하는 접근 법은 동일하지만 여기에 색인 개념이 추가되어 있다.
- 충분히 큰 공간을 할당 받은 다음 해시 함수를 이용하여 고유 색인을 생성한다.
- 그리고 이 고유 색인과 맞는 위치에 데이터를 저장한다.
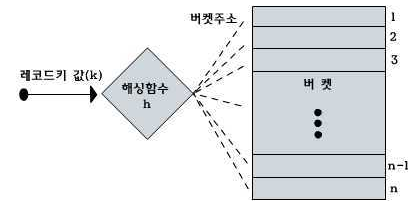
- 해쉬 함수를 사용하여 키를 해시값으로 매핑하고, 이 해시 값의 색인(index) 주소 값과 키를 함께 저장하는 자료구조를 해시 테이블(hash table) 이라고 한다.
- 색인 주소 값의 데이터가 저장되는 곳을 버킷(buckey) 또는 슬롯(slot) 이라고 한다.

- 위 그림의 각 버킷에는 아래와 같은 데이터가 저장된다.
| Index(Hash Value) | Data |
| 00 | |
| 01 | (Lisa Smith, 521-8976) |
| 02 | (John Smith, 521-1234) |
| 03 | |
| ... | ... |
| 13 | |
| 14 | (Sandra Dee, 521-9655) |
| 15 |
- 위 테이블과 같이 해시 테이블은 Data 값이 비어 있는 Index 값이 존재한다.
- 키의 전체 개수와 동일한 크기의 버킷을 가진 해시 테이블을 Direct-address table 이라 한다.
4.1. Direct-Address Table

(1) 장점
- 키 개수와 해시테이블 크기가 동일하기 때문에 해시 충돌 문제가 발생하지 않는다.
(2) 단점
- 위 그림에서 보면 전체 키의 갯수는 0~9까지 총 10개(K+U)이다. 그렇기 때문에 동일한 크기의 버킷을 가진 Direct-address table 도 10개(T)이다. 하지만 실제 사용하는 키(actual keys)가 전체 키(iniverse of keys)보다 적을 경우 사용하지 않는 키들을 위한 공간까지 마련해야 하는 탓에 메모리 효율성이 크게 떨어진다. 위 그림처럼 0, 1, 4, 6, 7, 9 를 위한 버킷은 굳이 만들어 놓을 필요가 없다.
4.2 실제 해시 테이블 운용
- Direct-address table 의 메모리 효율성 문제로 인해 보통의 경우 Direct-address table 보다는 "해시테이블 크기(m)가 실제 사용하는 키 개수(n)보다 적은 해시테이블"을 운용한다.
- 다뤄야할 데이터가 정말 많고, 메모리 등 리소스 문제도 생기기 때문이다.
5. 해시 충돌
- 하나의 원 데이터는 하나의 해시값만 가지지만, 하나의 해시값을 만들어낼 수 있는 원본 데이터는 매우 많다. 그 때문에 해시값만 가지고는 아무리 용을 써도 이미 뭉개진 원문을 복원해내는 것은 불가능하다. 따라서 비밀번호, 전자서명, 전자투표, 전자상거래와 같은 민감한 입력의 무결성을 검증할 때 사용된다.
- 따라서 어떤 해시 함수에서 해시 충돌이 일어나기 쉽다는 것은 보안 분야에서는 매우 민감한 문제에 해당한다. 데이터의 무결성과 직접적인 연관이 있기 때문이다.
- 현재까지 개발된 거의 모든 해시 함수는 해시 충돌의 문제가 확인된 상태이다. SHA-1과 SHA-256, SHA-512는 해시 충돌의 가능성이 이론적으로 제시되었다. 2014년 기준으로 문제가 없는 해시 표준으로는 SHA-3가 유일하다.
5.1 해시 충돌 예
- 0 ~ 10000까지 데이터를 담을 수 있는 리스트를 생성하고, 'tistory'란 단어에 해시 함수를 적용하여 '2642'란 색인이 생성되면 리스트 2642번 색인에 'tistory'를 저장하는 방식이다.
- 해시 함수는 언제나 동일한 해시 값을 반환하기 때문에 'tistory'를 입력하면 항상 2642란 색인이 나오므로 굳이 정렬하지 않고도 바로 찾을 수 있게 된다.
- 이후 나중에 입력된 'blog' 단어를 해시 함수에 넣었더니 '2642'란 색인으로 나온다면 'tistory'와 동일한 색인을 가지게 되는 문제가 발생한다.
5.2 해시 충돌 해결 방법
- 해시테이블의 크기를 유연하게 만들어 해결하는 분리 연결법(Separate Chaining) 과 해시테이블 크기는 고정시키되 저장해 둘 위치를 잘 찾는 데 관점을 둔 개발 주소법(Open Addressing) 등이 있다.
(1) 분리 연결법(Separate Chaining)
- 한 버킷당 들어갈 수 있는 엔트리의 수에 제한을 두지 않는 방법으로 모든 자료를 해시테이블에 담는다.
- 해당 버킷에 데이터가 이미 있다면 체인처럼 노드를 추가하여 다음 노드를 가리키는 방식으로 구현한다.
◇ 단점 : 메모리 문제를 야기할 수 있다.
- Linked List를 이용하는 방식이다. 각 index에 데이타를 저장하는 Linked list에 대한 포인터를 가지는 방식.

- 만약에 동일 index로 인해서 충돌이 발생하면 그 index가 가리키고 있는 Linked list에 노드를 추가하여 값을 추가한다.
- 데이타 추출은 key에 대한 index를 구한 후, index가 가리키고 있는 Linked list를 선형 검색하여 해당 key에 대한 데이터가 있는지를 검색하여 리턴한다.
- key를 삭제하는 것 역시, key에 대한 index가 가리키고 있는 Linked list에서 그 노드를 삭제하면 된다.
(2) 개방 주소법(Open Addressing)
- Chaining 과 달리 한 버킷당 들어갈 수 있는 엔트리가 하나뿐인 해시 테이블.
- hash table array의 빈공간을 사용하는 방법이다. (Linked list와 같은 추가적인 메모리 공간 사용 없이)
- 개방 주소법(Open Addressing)의 단점은 삭제가 어렵다는 것이다. 삭제를 했을 경우 충돌에 의해서 뒤로 저장된 데이타는 검색이 안될 수 있다.
- 개방 주소법(Open Addressing) 방식도 여러가지 구현 방식이 있는데, 가장 간단한 Linear probing 방식을 소개한다.
◆ Linear Probing
- Linear Probing 방식은 index에 대해서 충돌이 발생했을 때, index 뒤에 있는 버킷 중에 빈 버킷을 찾아서 데이타를 넣는 방식이다.
- 11을 키로 하는 데이타가 해시 함수를 거쳐 1이 키인 데이타와 충돌이 발생했을 경우, Linear Probing 에서는 아래 그림과 같이 충돌이 발생한 index(1) 뒤의 버킷에 빈 버킷이 있는지를 검색한다.

- 위 그림처럼 2번 버킷은 이미 index가 2인 값이 들어가 있고, 3번 버킷이 비어있기 때문에 3번 값에 넣는다.
- 검색할 때는, array[1]인 배열을 검색하는데, array[0]은 key가 일치하지 않기 때문에 array[1]을 검색해서 값을 찾는다.
(3) 리스트 크기 재배열
- 이렇게 충돌 해결을 한다고 해도 결과적으로 충돌로 인한 성능 저하는 막을 수 없다.
- 그래서 수용률이 일정량을 넘어가게 되는 경우에는 아예 리스트 자체의 크기를 키운 뒤에 재배열을 하는 방법을 사용한다.
- 다만, 이 과정 자체가 상당히 비용이 많이 드는 과정이라서 실시간으로 빠르게 처리해야 되는 환경에서는 무리가 있을 수 있다.
(4) 해시 테이블 확장 방식
- 큰 리스트를 하나 더 만들어서 적당한 타이밍에 몇 개씩 점진적으로 옮기다가 다 옮기면 기존의 테이블을 없애 확장하는 방식
- 다만 이 경우에는 메모리를 훨씬 더 많이 사용하게 된다.
(5) Consistent Hashing - 해시의 비트수를 늘이는 방법
- 해시의 비트수를 늘이는 방법도 있다.
- 항목 수가 적을 때에는 짧은(적은 비트 수) 해시와 작은 저장공간을 사용하다가 충돌이 잦아지면 비트수를 1비트 늘이고 저장공간도 2배로 늘인다.
- 그리고 항목을 점진적으로 확장된 공간으로 이전하게 함으로써 충돌을 줄일 수 있다.
- Consistent hashing이라고 하며 분산 데이터베이스에서 데이터의 일관성을 유지하기 위해 사용되고 있다.
(6) 해시 함수를 이용한 해시 충돌 해결 방법
- 해시테이블의 크기가 $m$이라면, 좋은 해시함수는 임의의 키 값을 임의의 해시 값에 매핑할 확률이 $\frac{1}{m}$이 될 것이다.
- 즉, 충돌나지 않고 해시 값을 고르게 만들어내는 해시함수가 좋은 해시함수이다.
① 나눗셈법 - Division method, 나머지 연산법
$h(k)=k mod m$
- 나눗셈은 간단하면서도 빠른 연산이 가능한 해시함수이다.
- 숫자로 된 키를 해시테이블 크기 $m$으로 나눈 나머지를 해시값으로 반환한다.
- 여기서 해시테이블 크기 $m$은 소수를 쓰며, 특히 2의 제곱수와 거리가 먼 소수를 사용하는 것이 좋다.
② 곱셈법 - Multiplication method
$h(k) = (kA mod 1) * m$
- 숫자로 된 키 $K$, $A$는 0과 1 사이의 실수 일 때 곱셈법은 다음과 같이 정의된다.
- $m$이 얼마가 되든 크게 중요하지는 않으며 보통 2의 제곱수로 정한다.
- 나눗셈 법보다는 느리고 2진수 연산에 최적화환 컴퓨터 구조를 고려한 해시함수이다.
③ Universal Hasing
- 다수의 해시함수를 만들고 이 해시함수의 집함 $H$에서 무작위로 해시함수를 선택해 해시값을 만드는 기법.
- $H$에서 무작위로 뽑은 해시함수가 주어졌을 때 임의의 키 값을 임의의 해시값에 매핑할 확률을 $\frac{1}{m}$로 만드려는 것이 목적이다.
6. 보안과 해시
(1) 보안 분야에서 해시를 사용하는 이유
- 키와 해시값 사이에 직접적인 연관이 없기 때문에 해시 값만 가지고는 키를 복원하기 어렵다
- 해시 함수의 결과물은 고정된 길이의 숫자이므로, 원래의 정보는 손실되므로 원데이터를 알 수 없다.
7. 알고리즘
- 유명한 해시 알고리즘으로 Message-Digest Algorithm(MD)과 Secure Hash Algorithm(SHA) 등이 있다.
(1) MD5
- 임의의 길이의 값을 입력 받아서 128비트 길이의 해시값을 출력하는 알고리즘이다.
- MD5는 단방향 암호화이기 때문에 출력값에서 입력값을 복원하는 것은 할 수 없다. 같은 입력값이면 항상 같은 출력값이 나오고, 서로 다른 입력값에서 같은 출력값이 나올 확률은 극히 낮다.
- 패스워드 암호화에 많이 사용되고, 패스워드를 MD5로 해시해서 나온 값을 저장해 두는 것이다.
- 현재는 MD5 알고리즘을 보안 관련 용도로 쓰는 것을 권장하지 않으며, 심각한 보안 문제를 야기할 수도 있다.
(2) SHA
- 1993년부터 미국 NSA가 제작하고 미국 국립표준기술연구소(NIST)에서 표준으로 채택한 암호학적 해시 함수이다.
- 1992년 SHA-0의 표준으로 정의되어 발표되었으나, 바로 위험성이 발견되어 이를 개선한 SHA-1이 발표되었고 이는 널리 사용되었다. SHA-0와 SHA-1은 160비트 해시값을 사용한다. SHA-1 역시 해시 충돌을 이용한 위험성이 발견되어 차세대 버전으로 넘어 가고 있다.
- 이를 개선한 버전이 SHA-2인데, 2001년 발표되었다. 해시 길이에 따라 SHA-225, SHA-256, SHA-384, SHA-512 비트를 선택해서 사용할 수 있으며, 당연히 해시 길이가 길수록 더 안전한다.
- 2012년 10월에 더욱더 안정성이 높은 방식으로 설계된 SHA-3 이 정식 발표되었다.
① SHA-2
- 대한민국 인터넷뱅킹은 SHA-256을 사용하고 있다. 2011년까진 2008년에 이미 뚫린 SHA-1을 사용 중이었다.
- 비트코인은 작업 증명에 SHA-256을 사용한다.
- TrueCrypt는 키 유도에 SHA-512를 사용할 수 있다.
반응형
'IT > 보안' 카테고리의 다른 글
| [보안] 정보보안기사 시스템 보안 - 윈도우 사용자 계정 및 그룹 (0) | 2020.09.21 |
|---|---|
| [보안] 바이러스, 맬웨어, 스파이웨어에 감염되는 이유 (0) | 2020.03.12 |
| [암호학] 하이브리드 암호시스템 (0) | 2019.11.27 |
| [암호학] 대칭키 방식 vs 비대칭키 방식 (0) | 2019.11.26 |
| [암호학] 비대칭키 - ECC, Elliptic Curve Cryptostystem (0) | 2019.11.26 |




댓글